
Observer-Effect-Free Profiling by Monitoring EM Emanations (MICRO 2016)
This paper suggests a new method for profiling program execution without instrumenting or otherwise affecting the profiled system. Spectral Profiling monitors EM emanations unintentionally produced by the profiled system, looking for spectral “spikes” produced by periodic program activity (e.g. loops). This allows Spectral Profiling to determine which parts of the program have executed at what time and by analysing the frequency and shape of the spectral “spike” obtain additional information such as the per iteration execution time of a loop.
This paper suggests a new method for profiling program execution without instrumenting or otherwise affecting the profiled system. Spectral Profiling monitors EM emanations unintentionally produced by the profiled system, looking for spectral “spikes” produced by periodic program activity (e.g. loops). This allows Spectral Profiling to determine which parts of the program have executed at what time and by analysing the frequency and shape of the spectral “spike” obtain additional information such as the per iteration execution time of a loop.

Scalable Virtual Address Translation for Processing-in-Memory
We used USIMM Simulator (http://www.cs.utah.edu/~rajeev/jwac12/) and added virtual address translation capability. After that, we modeled data transfer between CPU and PIM core with memory channels and measure their latency.
We used USIMM Simulator (http://www.cs.utah.edu/~rajeev/jwac12/) and added virtual address translation capability. After that, we modeled data transfer between CPU and PIM core with memory channels and measure their latency.
Array Bounds Checking Optimizations in LLVM
In this project, we inserted array bounds checking when the program is accessing an array. Some checks can be done in compile time, while others need to be executed in runtime. Then, after inserting the checks, we optimized them locally and globally. This means that, we remove some bounds checks because they were covered in previous checks or they were monotonic. For global optimizations, we wrote two dataflow equations, one backward and one forward to solve this in global CFG. For loops, we processed loop invariant and monotonic statements.
In this project, we inserted array bounds checking when the program is accessing an array. Some checks can be done in compile time, while others need to be executed in runtime. Then, after inserting the checks, we optimized them locally and globally. This means that, we remove some bounds checks because they were covered in previous checks or they were monotonic. For global optimizations, we wrote two dataflow equations, one backward and one forward to solve this in global CFG. For loops, we processed loop invariant and monotonic statements.

Source to source translator from C to C with OpenMP pragmas using Clang/LLVM
We will build the source to source translator using Clang(frontend) part of the LLVM. The
program is represented at higher level IR by the Clang in the form of ASTs (Abstract Syntax Tree). Here you will walk these trees and extract the necessary information from the respective loop nests. You will then set up dependence systems and first use GCD test. If it is inconclusive, then Banerjee Wolfe test is applied to prove independence. As discussed in the class, if a test can not prove independence, it must assume dependence. Only when it can establish independence can the loop be parallelized and then the openmp pragma is inserted.
We will build the source to source translator using Clang(frontend) part of the LLVM. The
program is represented at higher level IR by the Clang in the form of ASTs (Abstract Syntax Tree). Here you will walk these trees and extract the necessary information from the respective loop nests. You will then set up dependence systems and first use GCD test. If it is inconclusive, then Banerjee Wolfe test is applied to prove independence. As discussed in the class, if a test can not prove independence, it must assume dependence. Only when it can establish independence can the loop be parallelized and then the openmp pragma is inserted.
PERFORMANCE EVALUATION OF SHARED-MEMORY PROTOCOLS FACING GRAPH DATA
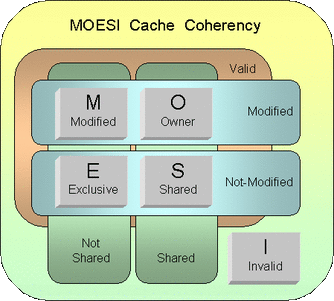
Graph applications are known for having low locality, and this lack of locality could be a major source of performance loss in these applications as the number of threads increases. To quantify performance loss due to memory transfer, two graph benchmarks, Graph500 and SSCA2, and one regular parallel benchmark, HeatPlate, were chosen. First, the performance loss was characterized by an instrumentation tool, PGOMP. Then, the MARSSx86 simulator was used to directly measure the MESI overhead. Finally, results analysis showed that MESI overhead was the source of up to 80 percent of performance loss in these graph benchmarks.
Graph applications are known for having low locality, and this lack of locality could be a major source of performance loss in these applications as the number of threads increases. To quantify performance loss due to memory transfer, two graph benchmarks, Graph500 and SSCA2, and one regular parallel benchmark, HeatPlate, were chosen. First, the performance loss was characterized by an instrumentation tool, PGOMP. Then, the MARSSx86 simulator was used to directly measure the MESI overhead. Finally, results analysis showed that MESI overhead was the source of up to 80 percent of performance loss in these graph benchmarks.
Implementation of Effective Hardware-Based Data Prefetching for High-Performance Processors
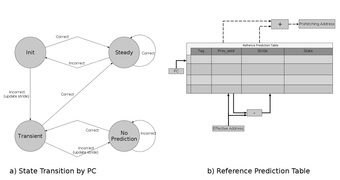
Due to progress pace of processors performance which is higher than memory latency, need of functions which help to reduce this gap is increasing every day. Hardware-Based data prefetching is one of the approaches to make this gap smaller than before. We decided to have a closer look at basic and correlated prefetching and analyze how they will improve performance in memory latency. Basic prefetching method tries to provide prefetching by taking into account adjacent data access by storing the strides and previous address while the correlated approach tries to take advantage of not only the adjacent accesses but also of those correlated changes in the outer loop level.
In this paper, implementation and analyze of simulation in GEMS–General Execution-driven Multiprocessor Simulator- are taken into consideration. We simulated a 16-core system and after modifying cache design in GEMS and adding Data Prefetching into it, we analyzed data by using PARSEC 2.0 benchmark.
By evaluation of the result we observed that basic prefetching scheme cannot be helpful on number of misses while correlated scheme can reduce it in most of the cases. But anyway on a multicore network neither have enhancement effect on speedup. There still huge amount of data which can be analyzed in future works.
Due to progress pace of processors performance which is higher than memory latency, need of functions which help to reduce this gap is increasing every day. Hardware-Based data prefetching is one of the approaches to make this gap smaller than before. We decided to have a closer look at basic and correlated prefetching and analyze how they will improve performance in memory latency. Basic prefetching method tries to provide prefetching by taking into account adjacent data access by storing the strides and previous address while the correlated approach tries to take advantage of not only the adjacent accesses but also of those correlated changes in the outer loop level.
In this paper, implementation and analyze of simulation in GEMS–General Execution-driven Multiprocessor Simulator- are taken into consideration. We simulated a 16-core system and after modifying cache design in GEMS and adding Data Prefetching into it, we analyzed data by using PARSEC 2.0 benchmark.
By evaluation of the result we observed that basic prefetching scheme cannot be helpful on number of misses while correlated scheme can reduce it in most of the cases. But anyway on a multicore network neither have enhancement effect on speedup. There still huge amount of data which can be analyzed in future works.
| final_report.pdf |

IED Detection in SAR Image
In this project, I implemented a paper which presents several methods for change detection in a pair of multi-look synthetic aperture radar (SAR) in matlab and C for a ACAPS Lab project funded by Army HPC research center. This paper applied those methods to detect mines while we use them to locate any change and eventually to detect any potential Improvised Explosive Device. Two groups of methods are compared. First, simple approaches with little computational complexity, differencing, Euclidean distance, and image ratioing are implemented although we do not expect them to show a good performance in presence of high speckle noise. Then Wiener prediction-based method, Subspace Method and Mahalanobis distance are implemented which incorporate second order statistic calculations in making a change decision in efforts to mitigate false alarms arising from the speckle noise, misregistration errors, and nonlinear variations in SAR images. We apply these methods on a pair of images which are simulated output of our Ground Penetrating Radar system in order to find any change and then calculate Receiver Operation Characteristic (ROC) to compare them. More bright changes are more important for human user since we do not need automatic alarm. The purpose of this project is applying this detector parallel to our SAR system and help solders to have safer sweep.
In this project, I implemented a paper which presents several methods for change detection in a pair of multi-look synthetic aperture radar (SAR) in matlab and C for a ACAPS Lab project funded by Army HPC research center. This paper applied those methods to detect mines while we use them to locate any change and eventually to detect any potential Improvised Explosive Device. Two groups of methods are compared. First, simple approaches with little computational complexity, differencing, Euclidean distance, and image ratioing are implemented although we do not expect them to show a good performance in presence of high speckle noise. Then Wiener prediction-based method, Subspace Method and Mahalanobis distance are implemented which incorporate second order statistic calculations in making a change decision in efforts to mitigate false alarms arising from the speckle noise, misregistration errors, and nonlinear variations in SAR images. We apply these methods on a pair of images which are simulated output of our Ground Penetrating Radar system in order to find any change and then calculate Receiver Operation Characteristic (ROC) to compare them. More bright changes are more important for human user since we do not need automatic alarm. The purpose of this project is applying this detector parallel to our SAR system and help solders to have safer sweep.
| report_ied_detection.pdf |
Inpainting the Colors
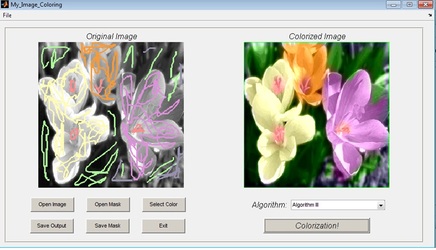
Main Idea of my Image Processing class final project is looking at colorization as an inpainting problem. This is an implementation of a paper by Prof. Sapiro from University of Minnesota.
Code is written in matlab and output is fascinating.
Main Idea of my Image Processing class final project is looking at colorization as an inpainting problem. This is an implementation of a paper by Prof. Sapiro from University of Minnesota.
Code is written in matlab and output is fascinating.
| inpainting_the_colors.pdf |
High performance spoken digit recognition with Artificial Neural Networks and HMM
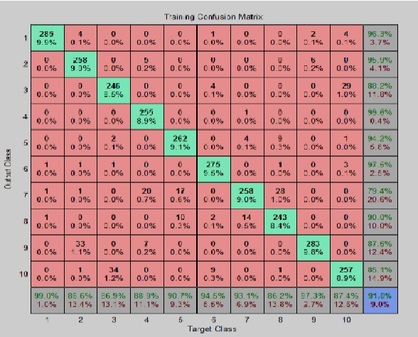
In my BS final project I implemented a spoken digit recognition system in Matlab using three different recognition models.
MLP neural network, LVQ neural network, Hidden Markov Model are three methods which I used and reached 93%, 88% and 96% accuracy.
In my BS final project I implemented a spoken digit recognition system in Matlab using three different recognition models.
MLP neural network, LVQ neural network, Hidden Markov Model are three methods which I used and reached 93%, 88% and 96% accuracy.
